前言:
在学校的时候对Kubernetes的向往来自于对“自动编排”这一愿景的向往。实际工作中接触到以后,发现各种知识扑面而来。比起直接深入细节,弄明白为什么需要Kubenetes的这些组件,为什么这些组件之间是如此互动的等问题,能够帮助我理清楚头绪。谨以此作为学习记录。
为什么需要Kubernetes?
回到我还在学校的时候,学生信息管理系统 (aka 选课系统)属实是人手一个的项目。问题来了,如果学校在同学们的吐槽声中,真的决定选中你写的学生选课信息管理系统作为升级版本,原本在你电脑里运行的二进制文件,真的能满足同学们的需求吗?
说不定经过一番折腾真的可以。首先,我们来尝试考虑同学们在选课的需求:
- 准确性:选课信息要准确,不同同学之间的课程信息不能弄混
- 可靠性:大量同学一起选课的时候不能崩
再尝试考虑学校的需求:
- 充分利用资源:除了选课高峰期,其他时间,系统不应该占据过多的服务器资源,以减少学校开支
- 减少人工干预的成本:选课期间老师们大多忙于解答选课问题或者处理排课冲突等问题,没有过多精力关注选课系统本身的问题
原本在课上写的代码可能包括如下部分:
- Gateway:系统前端,也负责转发流量到后端的部分
- Admin:身份验证
- Database:存储选课信息
- Controller:对选课逻辑等进行检查、处理(比如需要修满本系学分,同一个学生不同课程时间有重叠需要调整或者提醒等)
结合需求和现有条件,我们可以尝试用以下思路来满足同学与学校的需求:
- 对选课信息本身做持久化保存,加备份避免丢失 → Database增减
- 对登录同学身份做验证 → Admin将紧随选课同学数量的变化而感知到压力
- 选课期间增加Gateway数量,分流同学们的访问流量
- 在选课期间加服务器保证稳定,选课结束以后再撤掉多余的服务器;并将上述过程自动化
课堂代码之所以被我称之为单机游戏,是因为这些模块都会被放在一个项目下,逻辑可能有重叠交叉,编译时也一同编译。毕竟最开始我们的目标只是写完作业(啊这
但是这些组件在实际场景中真的能放在一起吗?显然选课期间与非选课期间,Gateway,Admin,Controller面临的压力是不同的。把应用作为一个整体一起增加、减少是不合适的。Database的数量与其他三个组件的数量比例也会随着同学数量的增减出现变化,人少的时候也许一个Database就能支持一个Gateway转发来的流量,但是人多的时候可能需要更多Database来存储信息。
这就引出了微服务(Microservice)的概念。根据Conway’s Law,设计复杂系统本身就是在设计各个组件(Component)之间的关系。微服务的设计思路帮助我们在实现中也把不同功能模块拆开,独立编译、更新、部署。这样我们用如下方式解决前面提到的一些问题:
- 在非选课期间学生选课调整需要保存新旧数据的情况下,只增加Database,其他组件数量不变
- 单独升级组件,Controller中的校验逻辑变化的时候,单独升级,无需改变其他组件
功能模块拆分后作为组件部署,意味着不同的组件可以被部署到不同的服务器上;就算是从我们的电脑(eg:Windows)转移到服务器(Linux),也同样要面临异质的底层的问题。聪明的你或许已经想到了虚拟机(Virtual Machine)。VM是一种虚拟化技术,它屏蔽了系统硬件间的差异,封装了硬件资源(内存、CPU、网卡)的调度,使得用户对底层硬件系统的区别无感。但是VM存在着体积大,启动慢的问题——毕竟一个虚拟机动辄几个G。试想,选课如火如荼的时候要加Admin,Gateway等组件,等待安装到启动,选课刚开始流量暴涨的前5分钟可能都不够下载虚拟机的。硬件层面的虚拟化并不能完全满足需求。
让我们尝试打开思路,可以虚拟化的不止是底层硬件。我们可以在系统之上的层次进行抽象。这就是容器(Container)。容器不在乎系统,它只会将应用,与应用所需的各种依赖(Dependency)和配置(Configuration)一起打包,使得它只要一要到系统资源就能开始运行。一来减少了包的大小便于传输到服务器上,二来提升了启动速度,能够快速响应需求。
问谁要资源呢?当然是位于容器与系统之间的管家了——Container Runtime Engine,常见的有Docker,Contaierd。Container Runtime Engine是一种系统间的抽象,使得我们要考虑的东西又少了一层。
容器与虚拟机是不同层次的抽象,二者虽然有区别但是可以并存,如下图所示
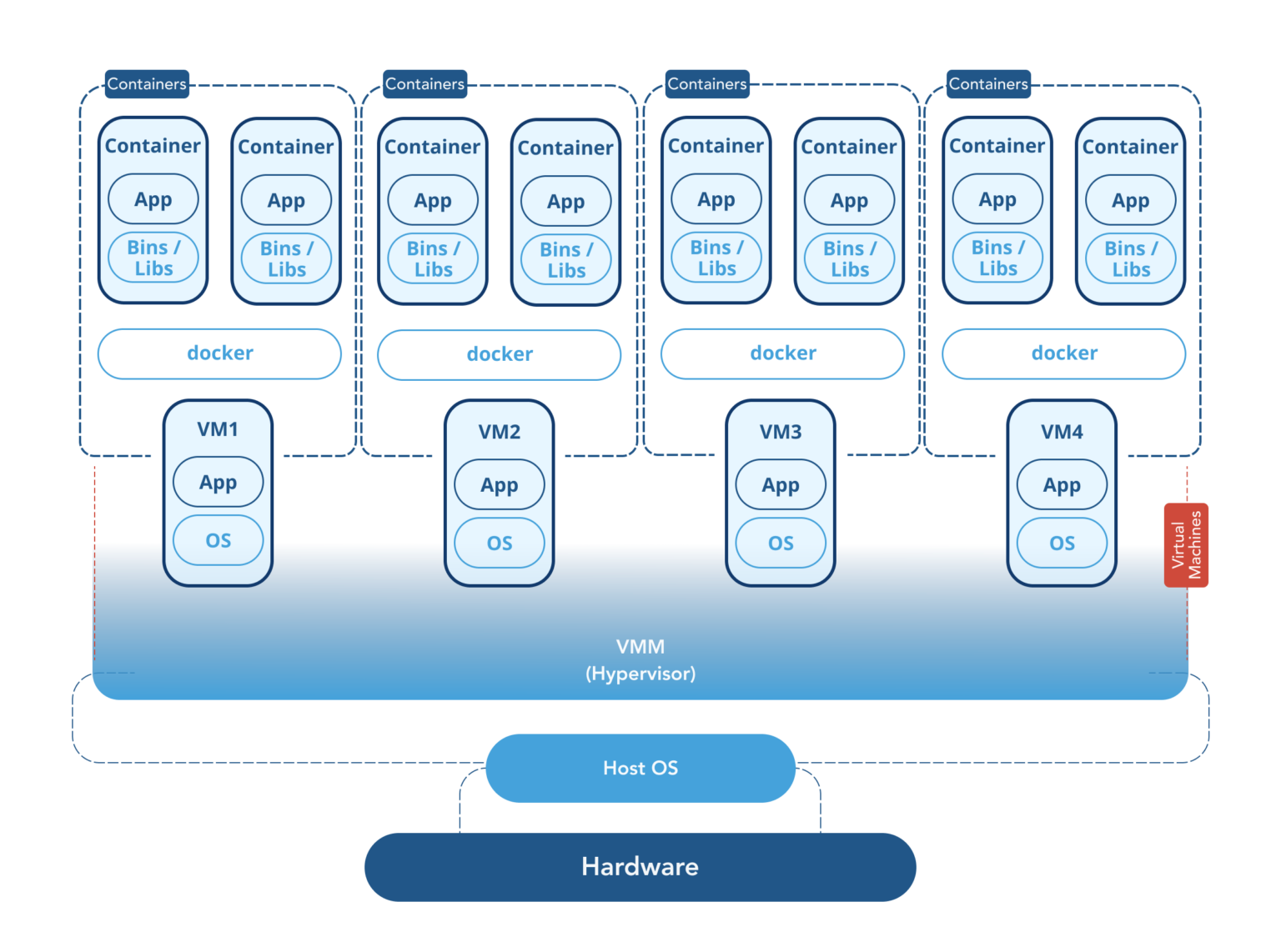
到目前为止,我们已经把一大坨课程作业zip包拆成了灵活的积木一样的容器,满足了以下场景的需求:
- 我们可以通过增加某组件容器数量来增强某一组件处理同学们选课请求的能力避免系统崩溃,也可以通过终止容器运行来释放冗余的资源,减少学校开支。
- 选课人多就加Gateway,Admin;高峰期结束以后再减少Gateway,Admin容器数量。
- 我们可以在不同的服务器上(甚至上云,如果学校懒得自己买服务器的话)部署,只要针对构造对应系统的镜像即可
但是部署编排如果需要人工干预又是一件麻烦事(想想学校的第二个需求):
- 高峰期需要加多少容器?是一起全部启动所有待加的容器,还是逐个上线?
- 不同容器之间的通讯与网络怎么配置?例如Controller怎么找到对应的Database来查询、更新所需的同学选课数据?
- 下线容器怎么样才能确保不会因为一次下线太多而影响正常服务?
可以看到,容器只解决了单个应用部署的问题,对于应用之间的资源调度与容器编排,实在是只能“只见树木,不见森林”。这就是Kubernetes(K8s)存在的意义——作为一种声明式的容器编排工具(Declarative Container Orchestrator)解决容器管理问题。
什么是声明式?意思是我们只需要告诉Kubernetes我们希望达到的状态(声明期望状态,而非说明具体要做什么),它会想办法把当前状态搞定成期望状态。至于怎么做到?我们可以不关心也可以关心——它提供了解决方案,我们也可以通过K8s约定的方式来增强它的能力(支持魔改)。到此,学校的第二个需求也有了解决方案——只需要规定选课和非选课期间需要保持的在线最小数量与最大数量,和我们期望部署、升级的步调,K8s会托管这一切。
TBC
事实上,K8s并不是唯一一个尝试解决容器调度编排问题的技术方案,但是它的确是目前最知名的方案,以至于提到云就绕不开K8s。K8s方案是怎样支持它目前具有的能力的,又是怎样发展成今天的样子?是它的什么特性使得它最终被大众认可?与其他方案相比优势何在?下一篇再继续讨论这些问题🎈
ref:
https://www.opsramp.com/guides/why-kubernetes/container-vs-vm/